
25周年のWikipediaは300以上の言語で6,500万件の記事、新たにAI企業と提携
Wikipediaは2001年1月15日に設立されました。25年後の今日、Wikipediaはインターネット上の知識の基盤となり、日常生活やAIチャットボットからジャーナリズム、クイズ大会まで、あらゆる分野の情報源となっ…
Wikipediaは2001年1月15日に設立されました。25年後の今日、Wikipediaはインターネット上の知識の基盤となり、日常生活やAIチャットボットからジャーナリズム、クイズ大会まで、あらゆる分野の情報源となっ…

スティーブ・カッツ(Steve Cutts)さんの2017年11月公開ショートアニメ「Happiness」は、幸福と充実感を求めるネズミの飽くなき探求の物語です。2025年4月に「Xbox “Wake Up&…
トムソン・ロイターは、子会社の法律調査プラットフォーム「Westlaw」の著作物を、AI企業ロス・インテリジェンス(Ross Intelligence)が不正使用したとしてAI著作権訴訟を起こしていました。今回の判決は、…
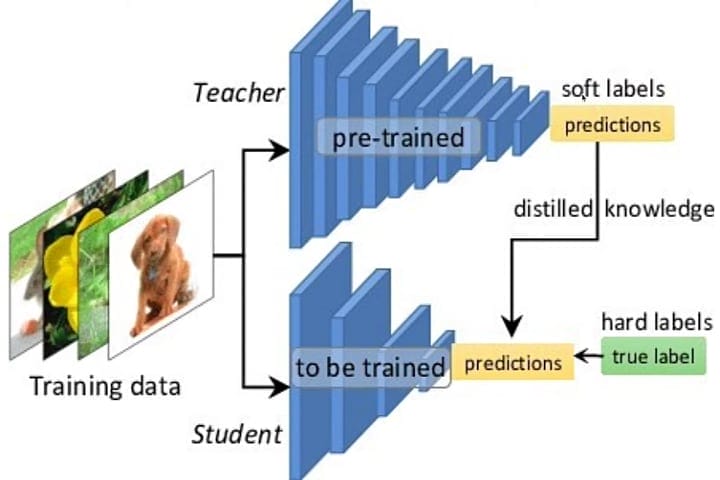
中国のAIスタートアップ企業ディープシーク(DeepSeek)が世界を驚かせた最新AIモデルは、「OpenAIのデータを学習させる手法を用いて開発された」と、AI・暗号資産政策責任者を務めるデービッド・サックス(Davi…

12月12日、ハーバード大学(Harvard Law School:HLS)は、約100万冊のパブリックドメインの書籍を含む高品質なデータセットを公開すると発表しました。このデータセットは HLSが Microsoftお…
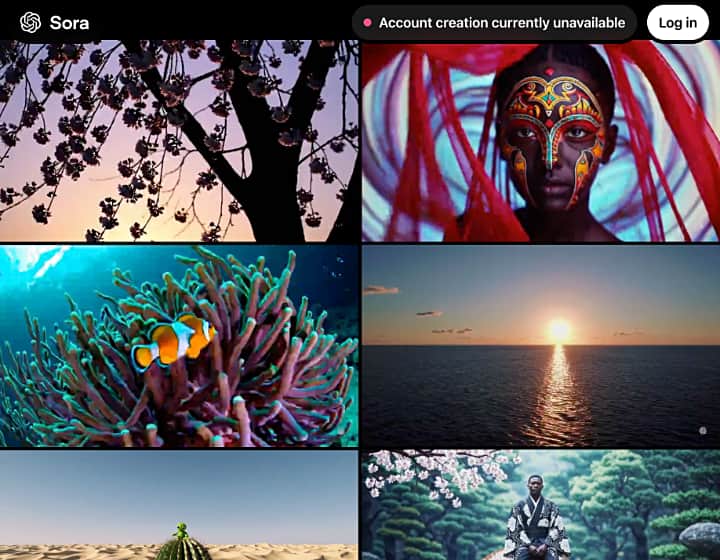
12月9日、OpenAIによる待望の動画生成AI「Sora」が公開されました。しかし11月26日、アーティストらが、公開前のSoraを“流出”させる騒動が起きていました。この騒動を受けて公開に踏み切ったのか? OpenA…

2024年1月1日、ミッキーマウスが初登場した1928年11月18日公開、ディズニー制作短編アニメーション映画蒸気船ウィリー(Steamboat Willie)と、プレーン・クレイジー(Plane Crazy)の米国での…

12月27日、米紙ニューヨーク・タイムズ(NYT)は、対話型生成AIのChatGPTを手掛ける米OpenAIと、OpenAIに出資しているマイクロソフトを提訴しました。NYTによると、著作権侵害でOpenAIとマイクロソ…

アバター(Avatar)は自分の分身となるキャラクターのことですが、AI技術によって精巧となり、さまざまな分野の企業が注目しています。アバター産業は2029年末までに5,270億ドル(約73兆7700億円)規模に拡大する…