レッド・パジャマ(RedPajama)は、完全にオープンソース化された大規模言語モデル(large language model: LLM)を開発するプロジェクトで、その第1段階として1兆2,000億以上のトークンを含むLLaMAトレーニングデータセットが公開されました。OpenAIのGPT-4をはじめとする大規模言語モデルの多くが「クローズドな商用モデル」、あるいは部分的にしかオープンではありません。完全にオープンソース化して疑念を排除し、安全性を高めた大規模言語モデルを開発します。 AIにおけるLinuxを開発する(AI’s Linux Moment)とも言えます。
<追記: 5/8>
- Releasing 3B and 7B RedPajama-INCITE family of models including base, instruction-tuned & chat models(5/5 Together)
- RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens(4/17 Together)
- AI’s Linux Moment: An Open-Source AI Model Love Note(1/30 Chris Ré.)

RedPajamaでは、以下の3段階で言語モデルの開発が進行します。
1.高品質で幅広い範囲をカバーする事前トレーニングデータの開発(4/17)
2.事前トレーニングデータで大規模に学習したベースモデルの開発(5/5)
3.ベースモデルを改良して使いやすく安全性を高めたチューニングデータとモデルの開発(—)
今回公開されたのは第1段階である事前トレーニングデータ「RedPajama-Data-1T」は、AI向けリポジトリサイトのHugging Faceで公開されています。
Redpajamaのベースになっているのは、Meta AIが2023年2月に発表した「LLaMA」です。LLaMAは1兆2,000億トークンのデータセットでトレーニングされた大規模言語モデルで、70億パラメータのモデルはGPT-4や、DeepMindのChincillaよりもずっと軽量でありながら同等のパフォーマンスを発揮するのが特徴です。
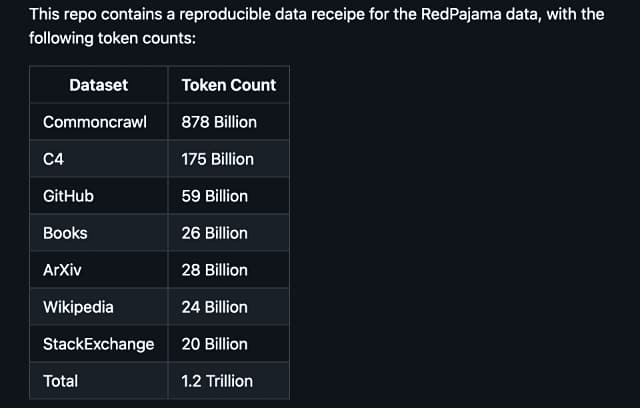
データセットの収集元に応じて「CommonCrawl」「C4」「GitHub」「arXiv」「Books」「Wikipedia」「StackExchange」という7つのデータスライスで構成されており、それぞれ慎重な前処理とフィルタリングが行われています。「RedPajama-Data-1T」はLLaMAで使われたデータセットを再現したものであり、各データスライスのトークン数もかなり近いものになっています。
現在の RedPajamaの取り組みは、Together、 Ontocord.aiと、 チューリッヒ工科大学のETH DS3Lab、 スタンフォード大学のStanford CRFM、 Hazy Research、 MILA Québec AI Instituteのコラボレーション・プロジェクトです。
RedPajamaの次の目標は、この「RedPajama-Data-1T」を使って強力な大規模言語モデルをトレーニングすることだと述べています。INCITEプログラムの一環として、オークリッジ国立研究所にあるOak Ridge Leadership Computing Facility(OLCF)の支援を受けて、フルセットデータのトレーニングをしており、最初のモデルは数週間(5月中)以内に利用可能になるようです。
OLCFの「Frontier」は、2022年5月にTOP500で 1.102エクサFLOPSを達成し、富岳を抜き世界1位のスーパーコンピュータとなっています。

- LLM オープンソース関連(Google検索)





