中国のAIスタートアップ企業ディープシーク(DeepSeek)が世界を驚かせた最新AIモデルは、「OpenAIのデータを学習させる手法を用いて開発された」と、AI・暗号資産政策責任者を務めるデービッド・サックス(David Sacks)氏が指摘しています。米国 OpenAIは、中国 DeepSeekがチャットボットの訓練に自社のAIモデルを利用したかどうかを調査しています。知識蒸留(Knowledge Distillation / arXiv)によると指摘されています。
- ディープシーク(DeepSeek)関連ニュース(Googleニュース検索)
- ディープシークはチャットGPTから「知識蒸留」=米AI責任者(1/29 WSJ)
- Deep Learningにおける知識の蒸留(1/12, 2018 codecrafthouse.jp)
- 知識蒸留(Knowledge Distillation)(5,2024 / Avintonジャパン)
DeepSeekは今月、人間の推論方法を模倣できる新しいオープンソースAIモデル DeepSeek-R1 を発表しました。DeepSeek-R1が数学的タスクや一般知識など、AI業界のさまざまなベンチマークにおいて、米国の大手AI企業と肩を並べるか、それを上回る性能を発揮するとしています。一方でその開発コストは、米国企業の数分の一で済んだということです。
1月28日、AI・暗号資産政策責任者のサックス氏は DeepSeekがOpenAIのモデルのアウトプットを参考に技術を開発した「相当な証拠」があると述べています。OpenAIの広報担当者は「AIのトップ企業として知的財産を守るための対策に取り組んでいる。米政府と緊密に協力することが極めて重要だと考えている」と説明しています。
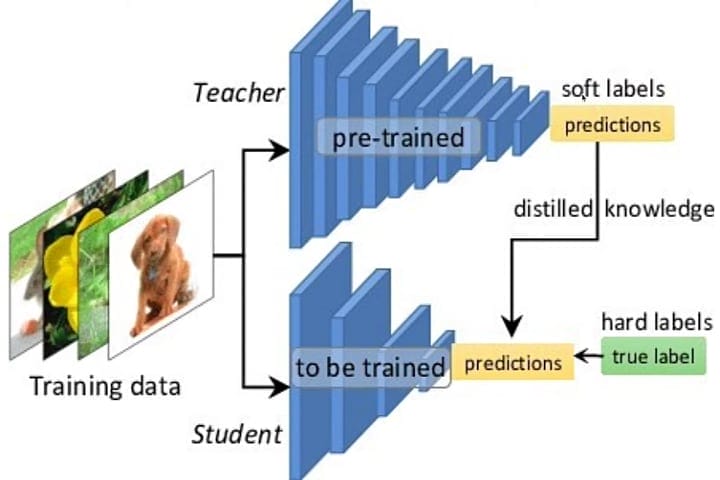
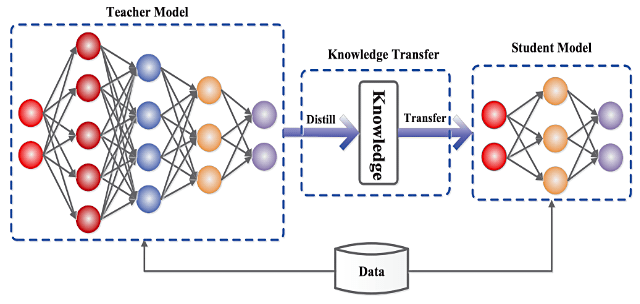
OpenAIは、自社のAIツールから大量のデータを抽出しようと、中国を拠点とする複数の組織がさまざまな試みをしたことを確認したと述べています。「知識蒸留」という技術的プロセスによって自前のAIモデルを訓練しようとした可能性が高いということです。
OpenAIは、同社のモデルから知識蒸留を行った疑いのあるアカウントを停止したと明らかにしました。こうした試みと関連のある主体を特定するため、OpenAIのモデルをホストしている MicroSoftと協力していると述べています。事情に詳しい関係者によると、OpenAIはDeepSeekも調査対象としています。
- Distilling the Knowledge in a Neural Network(9 Mar 2015 Geoffrey Hinton(ジェフリー・ヒントン), Oriol Vinyals, Jeff Dean(ジェフ・ディーン) / arXiv)
世界中で暗躍する産業スパイ。その時代の先端技術、飛行機や自動車、コンピュータ、家電製品などもリバースエンジニアリングにより「解析」「模倣」「価格低廉化」されてきました。いまは「生成AI」や「自動運転車」「宇宙」「バイオ」の先端分野など・・。ますます「知的財産権」が重要になります。ただ、オープンソースの場合は「それゆえ」の難しさもあります。
- アングル:ディープシーク盗用疑惑、AI「蒸留」阻止が困難な訳(1/30 ロイター)
中国の新AIツール「ディープシーク」、センシティブな話題の回答には中国検閲の限界が明らで、プロパガンダ色の強い情報を生成するようです。WSJが「天安門」「台湾」「チベット」などについて質問しています。
- ディープシークのAIに問う、天安門事件とは(1/31 WSJ)
世界中で開発競争が進む「AIモデル」が開発コストやベンチマークだけでその性能や価値が決定することはありません。意図的に差別や偏見、バイアスなどを生じさせて、追跡しにくい手段で「AIの意思決定」に影響を与えようとするものにすることも可能です。「AI原則、AI倫理、信頼できるAI、責任あるAI」などが問われ国際的にも一層重要になってきました。