12月6日(米国時間)、Google DeepMindは、かねてより開発を表明していた次世代のマルチモダール生成AIモデル「Gemini」を発表しました。現状は英語ながら、一部サービスは本日より利用開始しています。提供地域には日本も含まれています。「文字」「音声」「画像」「動画」「コード」などを同時に処理することが可能で、最上位モデルではGPT-4を超える性能を達成しているほか、同時に公開されたハンズオン(Hands-on)ムービーでは、極めて自然な受け答えをしている様子を確認できます。また、Pixel 8 Pro向けには、OSに組み込まれた「AICore」のアップデートとして、Gemini Nanoが搭載されるようです。
- Welcome to the Gemini era(Google DeepMind)
- Introducing Gemini: our largest and most capable AI model(12/6 blog.google)

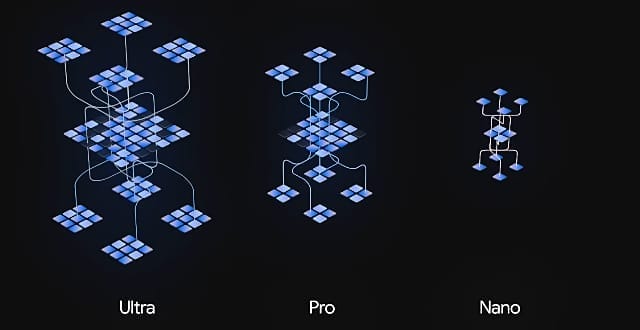
「Gemini Ultra」は、最大かつ最も有能なモデルで、2024年以降に利用可能になる予定です。「Gemini Pro」は、幅広いタスクに対応するための最良のモデルです。発表と同時に、Googleの「Bard」がGemini Proベースのものにアップグレードされ、既に利用可能になっています。「Gemini Nano」は、デバイス組み込み向けの最も効率的なモデルです。発表と同時にPixel 8 Proで利用可能となっています。
マルチモーダル(multimodal)とは、画像だけ・テキストだけといった形ではなく、人間と同じように「画像」「文字」「音声」「動画」といった複数の要素を同時に扱う能力のことです。最近の生成AIでは大きなテーマとなっていますが、Geminiは「ゼロから、マルチモーダルであることを前提にトレーニングした」ことが特徴としています。
Hands-on with Gemini: Interacting with multimodal AI
今日の大規模なモデルは、数千億、さらには数兆のパラメータを備えており、最も特殊なシステムであっても、場合によっては数か月に及ぶ広範なトレーニング期間を必要とします。これらの課題に対処するために、これまでで最も強力でスケーラブルで柔軟なアクセラレータである「Cloud TPU v5p」を発表しました。TPU(Cloud Tensor Processing Unit)は、YouTube、Gmail、Googleマップ、Google Play、Android などの AIを活用した製品のトレーニングとサービスの基盤として使用されています。
「Cloud TPU v5p」は、特に生成AIで使う大規模言語モデル(LLM)において、「TPU v4」の2.8倍の速度が出るとしています。今回はこれをマルチモダール生成AIモデル「Gemini」のトレーニングとサービス基盤に全面展開しています。
- 最大かつ高性能 AI モデル、Gemini を発表 – AI をすべての人にとってより役立つものに(12/7 Google Japan Blog)
- AI Gemini 関連情報(Google検索)