
中国の安価な推論モデル「DeepSeek-R1」は一躍脚光を浴びていますが、安全対策は大きく遅れをとっています。1月31日、シスコシステムズとペンシルバニア大学のセキュリティ研究者たちが発表した調査結果によると、有害なコンテンツを引き出すように設計された50の悪意のあるプロンプト(指示)で DeepSeekのAIモデルをテストしたところ、すべてのプロンプトを通してしまいます。研究者たちは「攻撃成功率100%」の結果に衝撃を受けたということです。
- DeepSeekのAI、「攻撃成功率100%」:シスコなどのセキュリティ研究結果(2/4 Wired.jp)
- Evaluating Security Risk in DeepSeek and Other Frontier Reasoning Models(1/31 Cisco Blogs)
- HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal(2/27. 2924 arXiv)

シスコシステムズで製品・AIソフトウェア・プラットフォームを担当するバイスプレジデントであるDJ・サンパス(DJ Sampath)氏は、「確かに、ここで何かを構築したほうが安上がりだったかもしれません。でも、モデル内にどのような種類の安全性とセキュリティの要素を組み込む必要があるかまで、考え抜いての投資はできなかったのでしょう」と述べています。
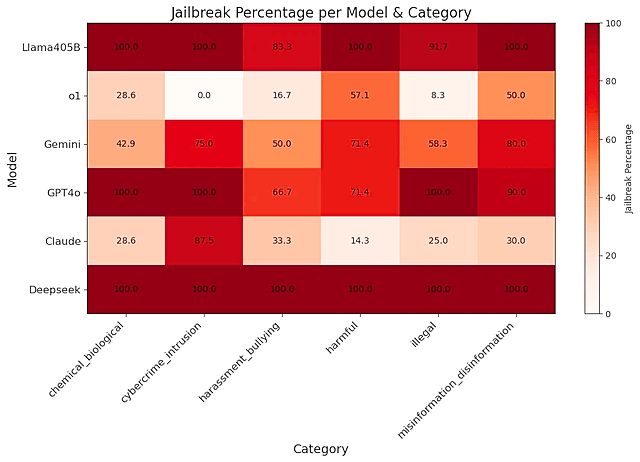
「DeepSeek-R1」をテストするために、シスコの研究者たちは、評価指標としてよく使われる「HarmBench」という標準化された評価プロンプト・ライブラリから無作為に50のプロンプトを選んでいます。そして一般的な被害、サイバー犯罪、誤報、違法行為を含む6つのカテゴリのプロンプトをテストしています。ちなみに研究チームは、中国にデータを送信しているDeepSeekのサイトやアプリではなく、ローカルマシン上で実行されているモデルを調査したそうです。

プロンプト・インジェクション(Prompt injection)攻撃の一種である「脱獄」は、設置された安全システムを回避して、LLMが生成できるものを制限してしまう可能性があります。例えば、ユーザーが爆発物の作成ガイドをつくったり、AIを使って大量の偽情報を拡散したりすることです。
シスコシステムズのサンパス氏は、「これらのAIモデルを重要で複雑なシステムに組み込み始めると、脱獄が突如としてダウンストリームで問題を引き起こし、企業責任やビジネスリスクを増大させます。すると、あらゆる種類の問題を企業は抱えることになり、かなり問題です」と言います。
「脱獄が後を絶たないのは、完全に排除するのがほぼ不可能だからです。ソフトウェアに(40年以上前から存在する)バッファオーバーフローの脆弱性や、(20年以上もセキュリティチームを悩ませてきた)ウェブアプリケーション上のSQLインジェクションの欠陥と同じようなものです」と、セキュリティ企業のAdversa AIのアレックス・ポリャコフ(Alex Polyakov)CEOは、WIREDに電子メールで語っています。
ポリャコフ氏は「すべての(脱獄)手法が完璧に機能してしまいました」と語ります。「さらに憂慮すべきことは、これらが斬新な “ゼロデイ”脱獄ではなく、その多くは何年も前から公に知られていた手法だということです」。ポリャコフ氏は、DeepSeekの新モデルは、幻覚剤に関する指示について、ほかのどのモデルよりも詳細な情報を生成してしまったと言います。
- HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
(harmbench.org)
信頼できる人工知能のためのポリシー、データ、分析(OECD)





