
Google、ETH Zurich(チューリッヒ工科大学)、NVIDIA、Robust Intelligenceに所属する研究者らが発表した論文「Poisoning Web-Scale Training Datasets is Practical」は、トレーニングデータセットの一部を改ざん(毒を仕込む)して機械学習モデルを攻撃する手法を解説、その研究報告が注目されています。「データポイズニング」(Data poisoning)と言われ、大規模言語モデル(LLM:Large Language Model)の「生成系AI」に意図的に差別や偏見、バイアスなどを生じさせて、追跡しにくい手段で「AIの意思決定」に影響を与えようとするものです。「AI原則、AI倫理、信頼できるAI、責任あるAI」などが問われ国際的にも一層重要になってきました。
- Poisoning Web-Scale Training Datasets is Practical(2/20 arxiv.org)
- The next big threat to AI might already be lurking on the web(3/2 zdnet.com)
- 「AIに毒を盛る」──学習用データを改ざんし、AIモデルをサイバー攻撃 Googleなどが脆弱性を発表(4/5 山下裕毅/ITmedia)

機械学習モデルのトレーニングデータセットには、インターネットをクロールして収集した大量のデータサンプルが含まれていますが、手動でのデータ収集や信頼性の保証については大規模になるほど不可能になります。
この実験では、下記の10種類の一般的なWebスケールデータセットを用い、この攻撃の実現可能性を実際に調査しています。その結果、60米ドル(約8,000円)程度で2022年にLAION-400MまたはCOYO-700Mデータセットの0.01%に毒を注入することに成功しています。この0.01%という値は、データセットのほんの一部にしか見えませんが、研究者らは「モデルを汚染するには十分」だと警告しています。
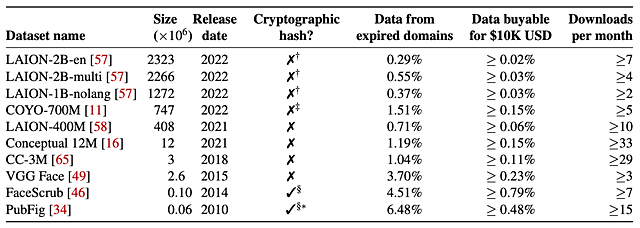
具体的には、攻撃者が期限切れのドメインをいくつか購入し、Webサイト内を変更することで攻撃を行ないます。運用されていたドメインに対する信頼を悪用するというものです。
また、攻撃(Frontrunning data poisoning)の例として Wikipediaを上げています。WikipediaのようなWebサイトでは、データのクロールを阻止するために、コンテンツのスナップショットを直接ダウンロードできるようにしています。攻撃者としては、スナップショットに含まれる前に、Wikipediaの記事に対して悪意ある修正を行って「毒」を盛ります。
論文の研究チームは、実験結果からデータポイズニング攻撃を防ぐための方策を提案しています。例えば、画像やその他のコンテンツが事後的に改ざんされないようにする「データ完全性(Data integrity)」などを述べています。

人間が作成するような絵や文章を生成することができる生成AI(Generative AI)は、私たちの社会を助けるというメリットばかりではなく、AIを利用して他人に害を及ぼすというデメリットも数多く指摘されるようになってきています。スタンフォード大学のHAI(Human-Centered AI)が、こうしたAIに関する多数のデータを収集・分析してまとめた報告書を公開しています。GIGAZINサイトが要約しています。
以下は、OECDや団体、企業が発表している人工知能に関する「AI原則、AI倫理、倫理AI、有益なAI、信頼できるAI、責任あるAI」などです。
- 42カ国がOECDの人工知能に関する新原則を採択(5/22, 2019 OECD)独立行政法人労働政策研究・研修機構
- AIを利活用するにあたって企業に求められる10のAI原則(PwC)
- 責任ある AI への取り組み(Google Cloud)
- Microsoft の責任ある AI の基本原則(Microsoft)





