早稲田大学の飯塚里志氏とシモセラ・エドガー氏、石川 博氏による画像補完の研究論文が、SIGGRAPH 2017に正式に採択されました。
ディープラーニングによって複雑な画像補完を行う手法を提案しています。画像中の不要な物体を消したり、人の顔を変化させたりもできます(^^)
動画では、面白い精度の高い画像補完技術を見ることができます。
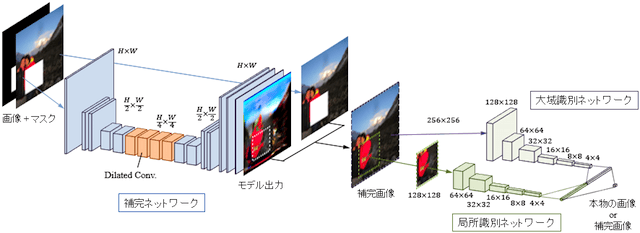
提案モデルは、補完ネットワーク、大域識別ネットワーク、局所識別ネットワークから構成されています(下図参照)
実際の画像補完に使用するのは補完ネットワークのみであり、2つの識別ネットワークは補完ネットワークの学習のために使用されます。補完ネットワークはすべての層が畳み込み層で構成、補完対象の損失領域を定義したマスクと画像が入力されると、損失領域が補完された画像が出力されます。損失領域以外の領域は入力画像に置き換えることで最終的な補完画像が得られます。
大域識別ネットワークは補完された画像全体を入力として補完画像が全体的に整合性のある構造になっているかを評価します。局所識別ネットワークは補完領域をパッチとして切り出して入力として補完領域のより詳細な自然さを評価します。
補完ネットワークは識別ネットワークが見分けられないように、識別ネットワークは補完ネットワークの出力画像を見抜くように、それぞれのネットワークを交互に学習していくことで補完ネットワークに自然な画像補完を学習させています。
- ディープネットワークによるシーンの大域的かつ局所的な整合性を考慮した画像補完 / Globally and Locally Consistent Image Completion(Website) 数多くの補完例を掲載